What are we making?
In this tutorial, you can build a tool to run several AI text prompts at once and compare their results. You can use it to explore what models ‘know’ about various concepts, communities, and cultures.
![A screenshot of three AI-generated images from the prompt The doctor is ['a Pakistani woman', 'a Black man', 'a white man']. The first image is a portrait, the second a cartoon, and the third is a hallway in shadows.](/_astro/criticalAItutorial2.BSLsu-HH_PnPmw.png)
A screenshot of three AI-generated images from the prompt The doctor is ['a Pakistani woman', 'a Black man', 'a white man']. The first image is a portrait, the second a cartoon, and the third is a hallway in shadows.
Prompt: The doctor is ['a Pakistani woman', 'a Black man', 'a white man']. Model: black-forest-labs/FLUX.1-dev
How to use it: Why compare prompts?
When we use generative AI to make text, code, or images, how are we able to understand its point of view? How does that point of view influence our work? How can we understand the perspectives the model absorbed from data if they are hidden behind the interface, if all we can do is write a prompt and hit submit?
Instead, we can build our own tools to test subtle variations that show how our word choices shape results. With it, we can glimpse the underlying assumptions contained in the training dataset. That gives us more information to decide how we select and use these models — and for which contexts.
Machine learning looks for how often patterns reappear, and it bases its training on principles like frequency and probability. It can amplify stereotypes and reduce concepts. For example, it may provide outdated or offensive images and ideas about careers for women and men, race and criminality, and sexuality and violence — reflecting the way its data were collected without critical care.
Here is an actual example created with the tool we will make, using the prompt, “The * has a job as a…” (where the asterisk is a wildcard or blank swapped out each time).
"The woman has a job as a nurse but she isn't sure how to make the most of it."
"The man has a job as a doctor but his life is filled with uncertainty. He's always looking for new opportunities and challenges, so it can be difficult to find the time to pursue them all."
"The non-binary person has a job as a nurse but she is not sure how to handle the stress of being an adult."
What can this prompt tell us about the roles and expectations of these figures as they are depicted by the model? How does it affect work you create using these models, knowing such assumptions are baked in?
For more about these questions, also see fantastic work on critical prompt programming by Yasmin Morgan (2022), Katy Gero (2023), and Minne Atairu (2024) that has inspired this tutorial.
This tutorial is Part 2 in a series of four tutorials that focus on using AI creatively and thoughtfully. Feel free to adapt them for your own critical exploration of AI systems:
- Part 1: Chatting With/About Code
- Part 3: Sentiment Training Dataset Explorer
- Part 4: The No-AI Critical AI Chatbot
How to make it
Step 1. Brainstorm prompts
A basic prompt may include WHAT/WHO is described, WHERE they are, WHAT they’re doing, or perhaps describing HOW something is done. For example:
"The * has a job as a..."
The asterisk is a wildcard, like a blank to be filled in. You will contribute words to fill that blank and the model will continue the sentence. In this case, fill in the blank with a personal characteristic. This adjective might describe their gender, sexuality, class, or race. It could also describe where they live or another quality about them. e.g. ["Pakistani woman", "Parisian man", "Peruvian person"].
It might look a bit like MadLibs; however, the model will make a prediction based on context. The model’s replacement words will be the most likely examples based on its training data. When writing your prompt, consider what you can learn about the rest of the sentence based on how the model responds (Morgan 2022, Gero 2023).
This example "The * was a..." comes directly from how its designers’ tested GPT-3. They filled in the blanks with jobs like ["engineer", "teacher", "nurse"] to test which jobs were most associated with particular genders.
Make a list of topics that interest you to try with the tool we will make. Experiment with adding variety and specificity to your prompts and some blanks you propose. Try different sentence structures and topics.
"The * family were boarding a train when they heard an announcement:"
Similarly, here you could fill in the wildcard with a description about the type of family, where they are from, or what kinds of communities they are part of, to see how the depiction of their travel might differ (Morgan 2022). Try updating your prompt with new variables (the choices you fill in for your wildcard) to see how your outputs change, or try a new prompt template altogether. Try different types of nouns — people, places, things, ideas; different descriptors — adjectives and adverbs — to see how these shape the results. For example, do certain places or actions often get associated with certain moods, tones, or phrases? Where are these based on outdated or stereotypical assumptions?
Here are a few more examples:
The doctor is wearing a ["lab coat", "suit", "headscarf"]
The man is riding a ["horse", "elephant", "motorcycle"]
Subtle changes in your inputs can lead to large changes in the output. Sometimes these also reveal large gaps in the model’s available knowledge. What does the model ‘know’ about communities who are less represented in its data? How has this data been limited?The ["queer", "trans", "straight"] person was stopped while on their way to ...
Step 2. Import the Hugging Face library
Now let’s make this example interactive, so that we can see it in action. Open the tutorial example in the p5.js Web Editor. Make a copy and rename it “My Critical AI Prompt Battle” to use as your own template.
Next, we use the Hugging Face library to work with machine learning models directly, and we will use p5.js to build our own interface to do so. Start by putting this code at the top of sketch.js:
import { HfInference } from 'https://cdn.jsdelivr.net/npm/@huggingface/inference@2.7.0/+esm';
This import phrase brings in a library (or module), and the curly braces let us specify a specific function (HfInference) from the library we want to use, so that we don’t have to import the entire thing. It also means that we have brought these particular functions into this “namespace” so that we can refer to it without using its library name in front of the function name.
Create a variable for your own access token: const HF_TOKEN = "" We don’t have a token yet, but we’ll get it soon.
Now declare a new case of HfInference and assign it to a variable named inference. We also attach it to our Hugging Face access token by passing in that empty variable we made:
const inference = new HfInference(HF_TOKEN);
Now let’s go get an access token from Hugging Face!
Hugging Face keeps a public repository of models and datasets that anyone can contribute to. In order to access the Hugging Face models, you’ll want to create your own an account and get an access token, so that they know it is you when you log on from your p5.js program. This is free.
After you create an account, click “Settings,” then “Access Token,” then “New Token.” Name your token something like “p5 Web Editor” and your choices for token type are “Fine-grained,” “Read,” or “Write.” Select “Write,” which means the token has permission interact with your Hugging Face account and make API1 calls as you. You don’t need to select specific fine-grained choices, but you can if you want. Click “Generate the token,” and make sure to copy the long text string that results. This is your token. Paste that long string into const HF_TOKEN = "hf_...".
Once you have your access token, we are ready to connect to Hugging Face to access their machine learning models.
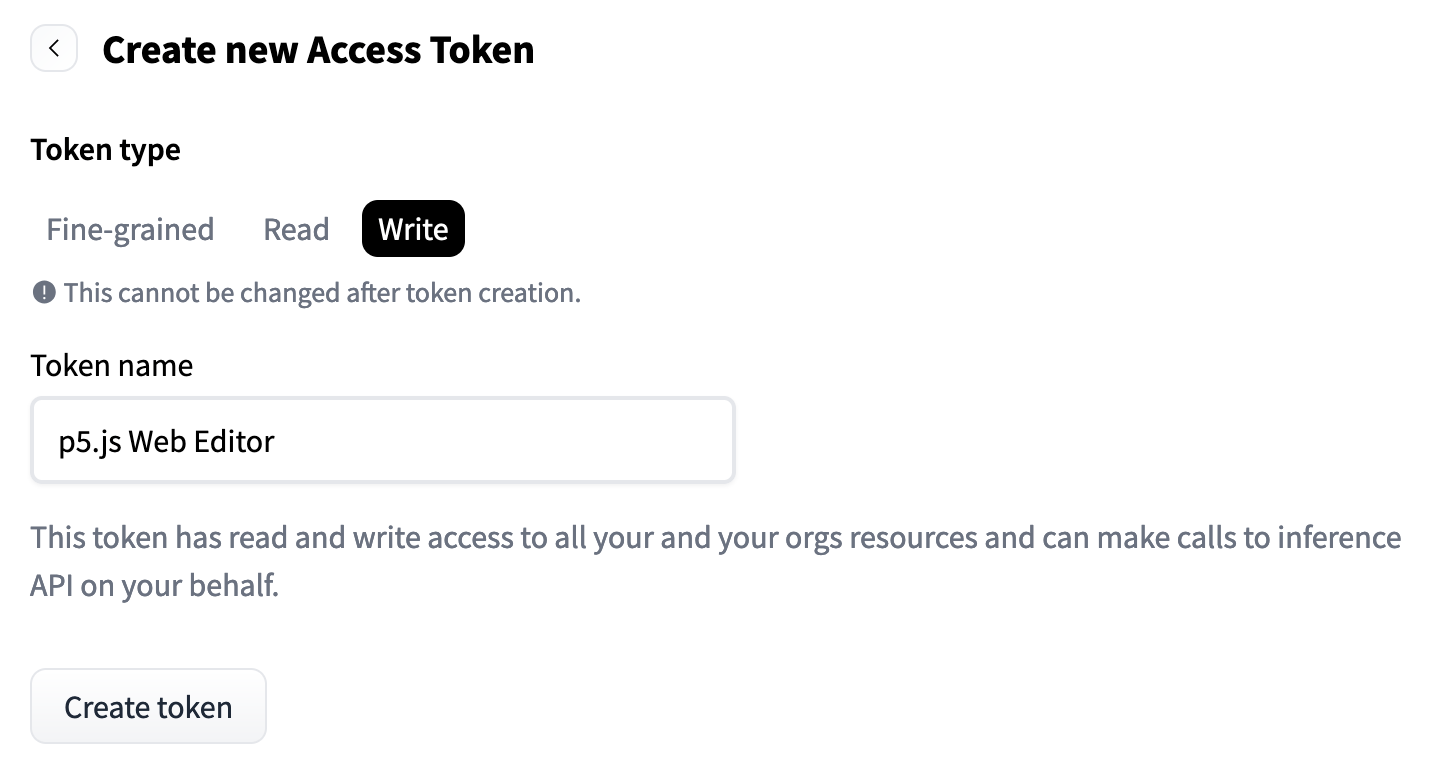
screenshot of access token setup
Step 3. Create global variables
Declare these variables at the top of your script so that they can be referenced in multiple functions throughout our project:
var PROMPT_INPUT = `` // a field for writing or changing a text value
var promptField // an html element to hold the prompt
var blanksArray = [] // an empty list to store all the variables we enter to modify the prompt
var modelOutput, resText, resImg // empty variables to store model results
We will be making a form that lets us write a prompt and send it to a model. The PROMPT_INPUT variable will carry the prompt we create. Choose one of your brainstormed prompts you’d like to use first to test your model. You can change it later; we’re making a tool for that!
For our first critical AI PROMPT_INPUT, we can start by trying this example: The * has a job as a.... Remember, we will provide several possible choices to replace the asterisk *.
The remaining variables promptField, blanksArray, modelOutput, resText, and resImg are created at the top of our program as empty global variables so that we can access their values from inside different functions at various parts of the program.
Step 4. Select the task and type of model
Let’s write a function to keep all our machine learning model activity together. The first task we will do is called “chat-completion.” Create a function About chatCompTask() and put async in front of the function call.async and await: Because model processing takes time, we want our code to wait for the model to work. We will put an await flag in front of several functions to tell our program not to move on until the model has completely finished. This prevents us from having empty strings as our results. Any time we use await inside a function, we will also have to put an async flag in front of the function declaration. For more about working with asynchronous functions, see Dan Shiffman’s video on Promises.
Here’s our basic model:
async function chatCompTask(prompt){
let MODEL = "mistralai/Mistral-7B-Instruct-v0.2"
const chatTask = await inference.chatCompletion({
model: MODEL,
messages: [{role: "user", content: prompt}],
max_tokens: 150
});
var result = chatTask
resText = result.choices[0].message.content;
console.log('finished chat task model run')
return resText
}
console.log(chatCompTask("The woman has a job as a...")
Inside this function, create a variable and name it MODEL. We’ll start with a default model ("mistralai/Mistral-7B-Instruct-v0.2") but this is a value you can change later as you explore the options available in Hugging Face Models.
Create another variable called const chatTask and set it equal to the inference library’s method chatCompletion, which runs the model. These preset functions come from the Hugging Face library. They have built in structures, and you can learn more about them by reading the API. We must set property messages: to send our prompt to the model. We can optionally set the properties including model, max_tokens, and a few others. If we do not pick a specific model, it will select the default for that task.
Next we process the results of the model by declaring a variable to handle the output: var result = chatTask. You can see the entire output by looking at a console.log(result).
Let’s look more closely at what the model outputs for us. In the example, we get a Javascript array, with an object that contains a property called content. We can extract just the string of text we are looking for with this code:
resText = result.choices[0].message.content.
For now, we end the function with It’s helpful to print out the whole output to the console. Seeing all the available properties, you may want to use these other parts of the results later. I also insert console logs to check to make sure the code has reached this point in running the program. They’re always optional, but so handy.return resText to send out only the part of the results we want to use in other parts of the program.
Then, we can run the function by trying console.log(chatCompTask("The woman has a job as a...") at the bottom of our code to test the model results in the console.
For example, one output we got from that prompt was, The woman has a job as a nurse and wishes for different jobs. The man has a job as an engineer and wishes for different careers. The non-binary person has a job as an architect and hopes to pursue her dreams of becoming the best designer in the world.
Step 5. Update model to process multiple prompts
Let’s rewrite our code so that our model processes more than one prompt at a time. Then we can compare the results. Here’s the new version:
async function chatCompGroupTask(pArray){
let MODEL = 'HuggingFaceH4/zephyr-7b-beta'
let resultArray = []
for (let p in pArray){
const chatTask = await inference.chatCompletion({
model: MODEL,
messages: [{role: "user", content: pArray[p]}],
max_tokens: 100
});
var result = chatTask.choices[0].message;
resText = result.content
resultArray.push(resText)
}
console.log(resultArray)
return [resultArray, MODEL]
}
First, you’ll notice we are trying out a new model named 'HuggingFaceH4/zephyr-7b-beta'. Just for fun. Find a list of models you can try on Hugging Face. They’re changing all the time.
The next difference is that, instead of loading one prompt in the function, we load an array of prompts. We then wrap the inference function in a for loop, and iterate over the array: for (let p in pArray){
We pass the results to a new array resultArray, and we also return the name of the model so that we can display it as metadata.
Step 6. Repeat this for the image model
From the example code, you’ll see a similar process is used to run the text-to-image model. It has different parameters (presets), including the height and width of the image and the model name, but otherwise the principle is similar:
async function textImgGroupTask(pArray){
let MODEL = 'black-forest-labs/FLUX.1-dev'
let resultArray = []
for (let p in pArray){
const blobImg = await inference.textToImage({
model: MODEL,
inputs: pArray[p],
parameters: {
guidance_scale: 3.5,
height: 512,
width: 512,
},
})
const url = await URL.createObjectURL(blobImg)
resultArray.push(url)
}
console.log(resultArray)
return [resultArray, MODEL]
}
Step 7. Use p5.js DOM elements to display model results
We already have a pre-built, friendly web interface using p5.js DOM functions, which lets you enter a prompt to send to the AI model. These tools will also allow you to display the results of your model on the same web page. The console is helpful for testing, so we will keep using console.log() as our backup.
Let’s start connecting our model to the web interface. Remember in a prior step we returned resultsArray and MODEL.
You’ll see that the line submitButton.mousePressed(displayOutput) means that when the SUBMIT button is pressed, the function displayOutput will run. It does several things:
- It checks what prompt has been input by the user.
- It creates an array of the variations on that prompt with the different word choices the user provided in the blanks.
- Then it sends that array to the text model and the image model.
- Then it handles the results output from each model by creating DOM elements to display those outputs.
Let’s look at the first part of the function:
async function displayOutput(){
console.log('submitButton just pressed')
// clear DOM outputs for new model ru
document.querySelector('#outText').innerHTML = ""
document.querySelector('#outInfo').innerHTML = ""
let placeholder = p5.createP("Please wait while all models are rendering").class('prompt').parent('#outPics')
placeholder.attribute('display', 'inherit')
// get current DOM inputs from prompt and blanks
PROMPT_INPUT = promptField.value() // grab update to the prompt if it's been changed
console.log("latest prompt: ", PROMPT_INPUT)
// create a list from the values in the blanks fields
let blanksValues = blanksArray.map(b => b.value())
console.log(blanksValues)
// fill in the prompt repeatedly with the values from blanks fields
blanksValues.forEach(b => {
let p = PROMPT_INPUT.replace(`*`,b)
promptArray.push(p)
})
console.log(promptArray)
In this section we have created a prompt array from the user’s inputs. Note that we marked this function as asynchronous because we need to wait for the model to run before continuing with code that follows this function.
Next the promptArray is sent to the image model and to the text model, with let getOutputPicURLs = await textImgGroupTask(promptArray) and let getOutputText = await chatCompGroupTask(promptArray):
// RUN IMAGE MODEL
let getOutputPicURLs = await textImgGroupTask(promptArray)
let res = getOutputPicURLs[0]
document.querySelector('#outPics').innerHTML = ""
for (let r in res){
let img = p5.createImg(res[r], promptArray[r]) // (url,alt-text)
img.size(300,300)
img.parent('#outPics')
}
// RUN TEXT MODEL
let getOutputText = await chatCompGroupTask(promptArray)
console.log(getOutputText[0])
Finally, we iterate over the results from getOutputPicURLs and getOutputText and create new paragraph elements or image elements to display for each one:
//fill in all text outputs
for (let i in getOutputText[0]){
p5.createP(promptArray[i]).class('prompt').parent('#outText')
p5.createP(getOutputText[0][i], true).parent('#outText')
}
// DISPLAY MODEL AND OTHER INFO
p5.createP("Text-to-Image Model: " + getOutputPicURLs[1]).parent('#outInfo')
p5.createP("Text-Generating Model: " + getOutputText[1]).parent('#outInfo')
// CLEAR VALUES FOR NEXT RUN
blanksValues, blanksArray, promptArray = []
PROMPT_INPUT = ``
}
We also create paragraph elements to display the original prompt and model as metadata. Finally we clear the fields for the next user input. Look for additional comments in the code for descriptions of each function. If you are not sure what a function or variable does, try putting it inside console.log() to print its results out to the console below your code.
Step 8. Bonus: Put your tool to the test
Is the model capable of representing a variety of contexts? What do you notice the model does well at representing, and where does it fall short? Where do you sense gaps, and how does it expose these or patch them over? Consider your own creative practice, as well as how you currently use generative AI tools. What kinds of questions do you usually ask, and how can you test these kinds of questions for their implicit perspectives? How do these perspectives impact your practice?
Try new varieties of prompts with more complex examples. Notice how the outputs shift with each word choice. What is different in each case that you didn’t expect? What environment is the subject in? Are they indoors or outdoors? Who are they around and what are they doing? What tropes are unsurprising?
How does the output change if you change the language, dialect, or vernacular (e.g. slang versus business phrasing)? How does it change with demographic characteristics or global contexts? (Atairu 2024). What’s the most unusual or obscure, most ‘usual’ or ‘normal’, or most nonsensical blank you might propose? Expand your tool: Currently, this tool lets you scale up how you prompt models. It compares word choices in the same basic prompt. You’ve also built a simple interface for accessing pre-trained models that does not require using another company’s interface. It lets you easily control your input and output, with the interface you built. You can keep playing with the p5.js DOM functions to build your interface with the HuggingFace API. There are many more aspects we could add to this interface that would let you adjust more features and explore even further. You might add more inputs, change up a parameter, add another model. You might also adapt this tool to compare wholly different prompts, or even to compare different models running the same prompt. You could even try different machine learning tasks (there are lots besides text and image generation) to use in your creative coding practice.
Takeaways
Here we have created a tool to test different kinds of prompts quickly and to modify them easily, allowing us to compare prompts at scale. By comparing how outputs change with subtle shifts in prompts, we can explore how implicit biases emerge from being repeated by and amplified through large-scale machine learning models. It helps us understand that unwanted outputs are not just glitches in an otherwise working system, and that every output (no matter how boring) contains the influence of its dataset. Reconsider neutral. No language or image model is neutral. Each result is informed by context. Each result reflects differences in representation and cultural understanding, which have been amplified by the statistical power of the model. Flag your work: Make it a habit to add text like “AI generated” to the title of any content you produce using a generative AI tool, and include details of your process in its description (Atairu 2024). Consider your choice of both words and tools. How does this help you think “against the grain” when working with AI models? Rather than taking the output of a system for granted as valid, how might you question or reflect on it? How will you use this tool in your practice?
Acknowledgments
These tutorials were created as part of Google Season of Docs 2024. Mentor: Emily Martinez. Advisor: Minne Atairu.
References
Atairu, Minne. 2024. “AI for Art Educators.” AI for Art Educators. https://aitoolkit.art/
Ciston, Sarah. 2023. “A Critical Field Guide for Working with Machine Learning Datasets.” Edited by Kate Crawford and Mike Ananny. doi.org/10.48550/arXiv.2501.15491 https://knowingmachines.org/critical-field-guide.
Katy Ilonka Gero, Chelse Swoopes, Ziwei Gu, Jonathan K. Kummerfeld, and Elena L. Glassman. 2024. Supporting Sensemaking of Large Language Model Outputs at Scale. In Proceedings of the CHI Conference on Human Factors in Computing Systems (CHI ‘24). Association for Computing Machinery, New York, NY, USA, Article 838, 1-21. https://doi.org/10.1145/3613904.3642139
Morgan, Yasmin. 2022. “AIxDesign Icebreakers, Mini-Games & Interactive Exercises.” https://aixdesign.co/posts/ai-icebreakers-mini-games-interactive-exercises
“NLP & Transformers Course.” Hugging Face. https://huggingface.co/learn/nlp-course/ An API (Application Program Interface) (API) helps your software access other software elsewhere. It provides the code interface to get information from another platform, instead of a visual or auditory interface (for example) that a person might access on a website. ↩Footnotes